elektronn3.modules.loss module¶
Loss functions
- class elektronn3.modules.loss.ACLoss(num_classes, region_weight=0.5)[source]¶
Bases:
ModuleActive Contour loss http://openaccess.thecvf.com/content_CVPR_2019/papers/Chen_Learning_Active_Contour_Models_for_Medical_Image_Segmentation_CVPR_2019_paper.pdf
Supports 2D and 3D data, as long as all spatial dimensions have the same size and there are only two output channels.
Modifications: - Using mean instead of sum for reductions to avoid size dependency. - Instead of the proposed λ loss component weighting (which leads to
exploding loss magnitudes for high λ values), a relative weight
region_weightis used to balance the components:ACLoss = (1 - region_weight) * length_term + region_weight * region_term
- class elektronn3.modules.loss.CombinedLoss(criteria, weight=None, device=None)[source]¶
Bases:
ModuleDefines a loss function as a weighted sum of combinable loss criteria.
- Parameters:
criteria (
Sequence[Module]) – List of loss criterion modules that should be combined.weight (
Optional[Sequence[float]]) – Weight assigned to the individual loss criteria (in the same order ascriteria).device (
device) – The device on which the loss should be computed. This needs to be set to the device that the loss arguments are allocated on.
- class elektronn3.modules.loss.DiceLoss(apply_softmax=True, weight=None, smooth=0.0)[source]¶
Bases:
ModuleGeneralized Dice Loss, as described in https://arxiv.org/abs/1707.03237.
Works for n-dimensional data. Assuming that the
outputtensor to be compared to thetargethas the shape (N, C, D, H, W), thetargetcan either have the same shape (N, C, D, H, W) (one-hot encoded) or (N, D, H, W) (with dense class indices, as intorch.nn.CrossEntropyLoss). If the latter shape is detected, thetargetis automatically internally converted to a one-hot tensor for loss calculation.- Parameters:
apply_softmax (
bool) – IfTrue, a softmax operation is applied to theoutputtensor before loss calculation. This is necessary if your model does not already apply softmax as the last layer. IfFalse,outputis assumed to already contain softmax probabilities.weight (
Optional[Tensor]) – Weight tensor for class-wise loss rescaling. Has to be of shape (C,). IfNone, classes are weighted equally.smooth (
float) – Smoothing term that is added to both the numerator and the denominator of the dice loss formula.
- class elektronn3.modules.loss.DistanceWeightedMSELoss(*args: Any, **kwargs: Any)[source]¶
Bases:
ModuleWeighted MSE loss for signed euclidean distance transform targets.
By setting
fg_weightto a high value, the errors in foreground regions are more strongly penalized. Iffg_weight=1, this loss is equivalent totorch.nn.MSELoss.Requires that targets are transformed with
elektronn3.data.transforms.DistanceTransformTargetPer-pixel weights are assigned on the targets as follows: - each foreground pixel is weighted by
fg_weight- each background pixel is weighted by 1.
- class elektronn3.modules.loss.FixMatchSegLoss(model, scale=1.0, enable_pseudo_label=True, confidence_thresh=0.9, ce_weight=None)[source]¶
Bases:
ModuleSelf-supervised loss for semi-supervised semantic segmentation training, very similar to the
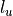 loss proposed in
FixMatch (https://arxiv.org/abs/2001.07685).
loss proposed in
FixMatch (https://arxiv.org/abs/2001.07685).The main difference to FixMatch is the kind of augmentations that are used for consistency regularization. In FixMatch, so-called “strong augmentations” are applied to the (already “weakly augmented”) inputs. Most of these strong augmentations only work for image-level classification. In
FMSegLoss, only simple, easily reversible geometric augmentations are used currently (random xy(z) flipping and random xy rotation in 90 degree steps). TODO: Add more augmentationsThis loss combines two different well-established semi-supervised learning techniques:
consistency regularization: consistency (equivariance) against random flipping and random rotation augmentatations is enforced
pseudo-label training: model argmax predictions are treated as targets for a pseudo-supervised cross-entropy training loss This only works for settings where argmax makes sense (not suitable for regression) and can be disabled with
enable_psuedo_label=False.
- Parameters:
model (
Module) – Neural network model to be trained.scale (
float) – Scalar factor to be multiplied with the loss to adjust its magnitude. (If this loss is combined with a standard supervised cross entropy,scalecorresponds to the lambda_u hyperparameter in FixMatchenable_pseudo_label (
bool) – Ifenable_pseudo_label=True, the inner loss is the cross entropy between the argmax pseudo label tensor computed from the weakly augmented input and the softmax model output on the strongly augmented input. Since this internally usestorch.nn.CrossEntropyLoss, themodelis expected to give raw, unsoftmaxed outputs. This only works for settings where computing the argmax and softmax on the outputs makes sense (so classification, not regression). Ifenable_pseudo_label=False, a mean squared error regression loss is computed directly on the difference between the two model outputs, without computing or using pseudo-labels. In this case, the loss is equivalent to theRloss proposed in “Transformation Consistent Self-ensembling Model for Semi-supervised Medical Image Segmentation” (https://arxiv.org/abs/1903.00348). This non-pseudo-label variant of the loss can also be used for pixel-level regression training.confidence_thresh (
float) – (Only applies ifenable_pseudo_label=True.) The confidence threshold that determines how confident the model has to be in each output element’s classification for it to contribute to the loss. All output elements where none of the softmax class probs exceed this threshold are masked out from the loss calculation and the resulting loss is set to 0. In the FixMatch paper, this hyperparameter is called tau.ce_weight – (Only applies if
enable_pseudo_label=True.) Class weight tensor for the inner cross-entropy loss. Should be the same as the weight for the supervised cross-entropy loss.
- static get_random_augmenters(ndim)[source]¶
Produce a pair of functions
augment, reverse_augment, where theaugmentfunction applies a random augmentation to a torch tensor and thereverse_augmentfunction performs the reverse aumentations if applicable (i.e. for geometrical transformations) so pixel-level loss calculation is still correct).Note that all augmentations are performed on the compute device that holds the input, so generally on the GPU.
- Return type:
Tuple[Callable[[Tensor],Tensor],Callable[[Tensor],Tensor]]
- class elektronn3.modules.loss.FocalLoss(*args: Any, **kwargs: Any)[source]¶
Bases:
ModuleFocal Loss (https://arxiv.org/abs/1708.02002)
Expects raw outputs, not softmax probs.
- class elektronn3.modules.loss.GAPTripletMarginLoss(*args, **kwargs)[source]¶
Bases:
TripletMarginLossSame as
torch.nn.TripletMarginLoss, but applies global average pooling to anchor, positive and negative tensors before calculating the loss.
- class elektronn3.modules.loss.MaskedMSELoss(*args, **kwargs)[source]¶
Bases:
ModuleMasked MSE loss where only pixels that are masked are considered.
Expects an optional binary mask as the third argument. If no mask is supplied (
None), the loss is equivalent totorch.nn.MSELoss.
- class elektronn3.modules.loss.MixedCombinedLoss(*args: Any, **kwargs: Any)[source]¶
Bases:
ModuleDefines a loss function as a weighted sum of combinable loss criteria for multi-class classification with only single class ground truths.
- For each voxel, we construct a 2 channel output after the softmax:
channel 0: background (actual background + all but one classes) = (1-channel 1) channel 1: foreground (the one class to which the target corresponds)
- Parameters:
class_weight – a manual rescaling weight given to each class.
criteria – List of loss criterion modules that should be combined.
criteria_weight – Weight assigned to the individual loss criteria (in the same order as
criteria).device – The device on which the loss should be computed. This needs to be set to the device that the loss arguments are allocated on.
eps –
- class elektronn3.modules.loss.NorpfDiceLoss(*args: Any, **kwargs: Any)[source]¶
Bases:
ModuleGeneralized Dice Loss, as described in https://arxiv.org/abs/1707.03237,
Works for n-dimensional data. Assuming that the
outputtensor to be compared to thetargethas the shape (N, C, D, H, W), thetargetcan either have the same shape (N, C, D, H, W) (one-hot encoded) or (N, D, H, W) (with dense class indices, as intorch.nn.CrossEntropyLoss). If the latter shape is detected, thetargetis automatically internally converted to a one-hot tensor for loss calculation.- Parameters:
apply_softmax – If
True, a softmax operation is applied to theoutputtensor before loss calculation. This is necessary if your model does not already apply softmax as the last layer. IfFalse,outputis assumed to already contain softmax probabilities.weight – Weight tensor for class-wise loss rescaling. Has to be of shape (C,). If
None, classes are weighted equally.